源码阅读 libevent - 数据结构:哈希表
libevent 源码中除了 queue.h 文件中定义了 5 种数据结构,在 ht-internal.h 文件中定义了另一个重要的数据结构:哈希表。
本系列大部分文章介绍
linux系统下libevent的源码,但libevent在linux环境下并没有用到哈希表结构,但学习libevent中哈希表的实现非常有助于对哈希表结构的理解。
哈希表定义
哈希表定义宏
#define HT_HEAD(name, type) \
struct name { \
struct type **hth_table; /* The hash table itself. */ \
unsigned hth_table_length; /* How long is the hash table? */ \
unsigned hth_n_entries; /* How many elements does the table contain? */ \
unsigned hth_load_limit; /* How many elements will we allow in the table before resizing it? */ \
int hth_prime_idx; /* Position of hth_table_length in the primes table. */ \
}
#define HT_ENTRY(type) \
struct { \
struct type *hte_next; \
unsigned hte_hash; /* Hash cache */ \
}哈希表结构
与双向链表一样,我们通过测试程序来看哈希表在内存中的结构:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "ht-internal.h"
typedef struct Node {
int key;
int value;
HT_ENTRY(Node) map_node;
} Node;
HT_HEAD(INT_MAP, Node);
static inline unsigned hashfn(struct Node *e) {
unsigned h = (unsigned) e->key;
h += (h>> 2) | (h << 30);
return h;
}
static inline int eqfn(struct Node *e1, struct Node *e2) {
return e1->key == e2->key;
}
HT_PROTOTYPE(INT_MAP, Node, map_node, hashfn, eqfn)
HT_GENERATE(INT_MAP, Node, map_node, hashfn, eqfn, 0.5, malloc, realloc, free)
int main(void) {
struct INT_MAP table;
HT_INIT(INT_MAP, &table);
int a = 0;
for (int i = 0; i < 20; i++) {
srand(time(NULL) + a % 1000003);
a = rand() % 1000003;
Node* new_item = malloc(sizeof(Node));
new_item->key = a;
new_item->value = i;
HT_INSERT(INT_MAP, &table, new_item);
}
printf("\n[HEAD]: **hth_table = %p\n"
"hth_table_length = %d\n"
"hth_n_entries = %d\n"
"hth_load_limit = %d\n"
"hth_prime_idx = %d\n\n",
table.hth_table, table.hth_table_length, table.hth_n_entries, table.hth_load_limit, table.hth_prime_idx);
for (int i = 0; i < table.hth_table_length; i++) {
if (table.hth_table[i]) {
printf("[TABLE]: [%03d] - [%p]", i, table.hth_table[i]);
Node* item = table.hth_table[i]->map_node.hte_next;
while (item) {
printf("--> [%p]", item);
item = item->map_node.hte_next;
}
printf("\n");
}
}
Node** item;
HT_FOREACH(item, INT_MAP, &table) {
printf("[NODE]: Key = %-8d Value = %-5d Next = %-10p Addr = %-10p\n",
(*item)->key, (*item)->value, (*item)->map_node.hte_next, *item);
}
return 0;
}程序执行结果如下:
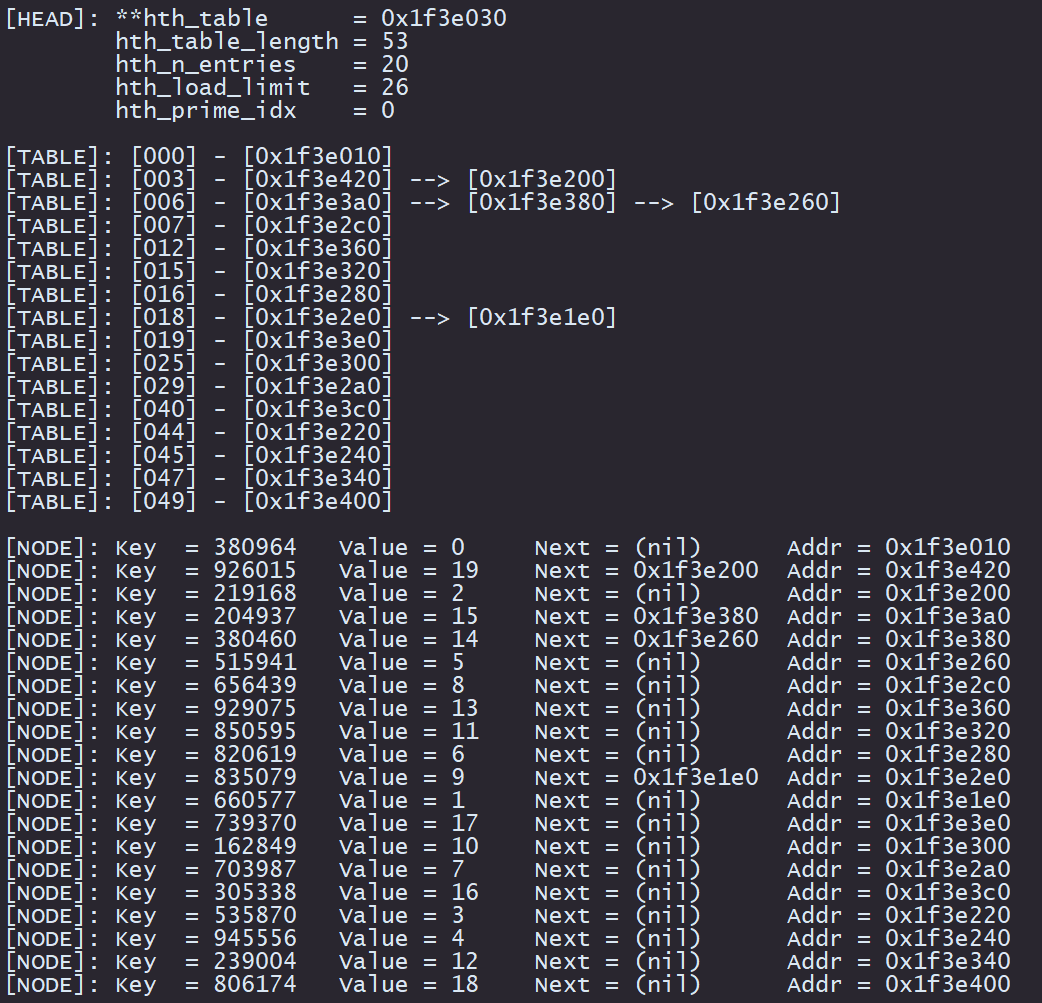
哈希表头
可以看出,libevent 中定义的哈希表头结构体意义如下:
hth_table:哈希表的存储位置hth_table_length:哈希表的长度hth_n_entries:哈希表的元素个数hth_load_limit:哈希表元素限制,超过限制后需要进行哈希表扩容hth_prime_idx:哈希表容量等级,libevent 的哈希表存在 26 个容量等级
哈希冲突的解决
libevent 的哈希表是使用链地址法解决冲突问题的,这一点可以从 hth_talbe 成员变量看到。它是一个二级指针,其指向了哈希表的元素所在的地址。
哈希函数
libevent 中的哈希函数由使用者定义,上述测试代码中使用了和 libevent 中一样的哈希函数:模 (%)。
libevent中哈希表的代码存在大量的宏定义,可读性低,本文通过gcc的-E选项结合AStyle将上文中的测试程序转化为了可读性较好的代码,以下分析均采用转化后的代码片段。
哈希表的访问
查找
static inline struct Node ** INT_MAP_HT_FIND_P_(struct INT_MAP *head, struct Node *elm) {
struct Node **p;
if (!head->hth_table) return NULL;
p = &((head)->hth_table[((elm)->map_node.hte_hash) % head->hth_table_length]);
while (*p) {
if (eqfn(*p, elm)) return p;
p = &(*p)->map_node.hte_next;
}
return p;
}
static inline struct Node * INT_MAP_HT_FIND(const struct INT_MAP *head, struct Node *elm) {
struct Node **p;
struct INT_MAP *h = (struct INT_MAP *) head;
do {
(elm)->map_node.hte_hash = hashfn(elm);
} while (0);
p = INT_MAP_HT_FIND_P_(h, elm);
return p ? *p : NULL;
}INT_MAP_HT_FIND_P_ 和 INT_MAP_HT_FIND 均为哈希表的查找函数,两者的区别是:
- 返回数据类型不同:
INT_MAP_HT_FIND_P_返回值是 Node**,是一个二级指针,指向的是保存被查找哈希元素的地址的指针变量 > 比如:hth_table[1]中保存着带查找元素的地址,该函数则返回的是hth_table[1]的地址信息。INT_MAP_HT_FIND返回值是 Node*,指向查找到的哈希元素
- 查找步骤差别:
INT_MAP_HT_FIND_P_直接使用计算过的哈希值进行查找INT_MAP_HT_FIND重新使用哈希函数计算哈希值后进行查找
- 判断查找成功与否方式不同:
INT_MAP_HT_FIND_P_返回值始终非空,需要判断其返回值指向的数据是否为NULL来确认查找结果INT_MAP_HT_FIND_P_查找失败时,返回的地址可以作为该元素插入的地址进行插入操作INT_MAP_HT_FIND未查找到对应元素时返回值为NULL
遍历
static inline struct Node ** INT_MAP_HT_START(struct INT_MAP *head) {
unsigned b = 0;
while (b < head->hth_table_length)
{
if (head->hth_table[b]) return &head->hth_table[b];
++b;
}
return NULL;
}
static inline struct Node ** INT_MAP_HT_NEXT(struct INT_MAP *head, struct Node **elm) {
if ((*elm)->map_node.hte_next) return &(*elm)->map_node.hte_next;
else {
unsigned b = (((*elm)->map_node.hte_hash) % head->hth_table_length)+1;
while (b < head->hth_table_length) {
if (head->hth_table[b]) return &head->hth_table[b];
++b;
}
return NULL;
}
}遍历的三要素:
- 遍历的起始节点
- 依次查找哈希表数组中的每一个元素,首个非空的元素即为起始节点
- 下一个节点的获取
- 如果当前节点的
next指针非空,则next指针指向的位置为下一个节点 - 如果当前节点的
next指针为空,则继续遍历哈希表数组中的元素
- 如果当前节点的
- 遍历的结束条件
- 如果遍历完哈希表数组遍历完成(根据哈希表长度值
hth_table_length判断),则遍历结束
- 如果遍历完哈希表数组遍历完成(根据哈希表长度值
哈希表的操作
哈希表的基础操作
/* 哈希表的判空 */
#define HT_EMPTY(head) ((head)->hth_n_entries == 0)
/* 哈希表的表数组大小 */
#define HT_SIZE(head) ((head)->hth_n_entries)
/* 哈希表的表占用的内存大小 */
#define HT_MEM_USAGE(head) (sizeof(*head) + (head)->hth_table_length * sizeof(void*))以上接口较为简单,不进行过多说明。
初始化
static inline void INT_MAP_HT_INIT(struct INT_MAP *head) {
head->hth_table_length = 0;
head->hth_table = NULL;
head->hth_n_entries = 0;
head->hth_load_limit = 0;
head->hth_prime_idx = -1;
}哈希表的初始化其实就是对表头数据进行初始化。
插入
static inline void INT_MAP_HT_INSERT(struct INT_MAP *head, struct Node *elm) {
struct Node **p;
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit)
INT_MAP_HT_GROW(head, head->hth_n_entries + 1);
++head->hth_n_entries;
do {
(elm)->map_node.hte_hash = hashfn(elm);
} while (0);
p = &((head)->hth_table[((elm)->map_node.hte_hash) % head->hth_table_length]);
elm->map_node.hte_next = *p;
*p = elm;
}插入操作可分为 3 ~ 4 个步骤:
- 判断当前哈希表是否需要扩容
- 调用哈希函数计算新插入数据的哈希值
- *(需要时) 解决哈希冲突
- 头插法插入新数据(后插入的数据在链表头)
需要注意的是:
libevent的插入函数INT_MAP_HT_INSERT并没有对重复的哈希key进行判断,所以根据不同的应用场景,可能会有不同的应用方式。
修改 & 插入
static inline struct Node * INT_MAP_HT_REPLACE(struct INT_MAP *head, struct Node *elm) {
struct Node **p, *r;
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit)
INT_MAP_HT_GROW(head, head->hth_n_entries + 1);
do {
(elm)->map_node.hte_hash = hashfn(elm);
} while (0);
p = INT_MAP_HT_FIND_P_(head, elm);
r = *p;
*p = elm;
if (r && (r!=elm)) {
elm->map_node.hte_next = r->map_node.hte_next;
r->map_node.hte_next = NULL;
return r;
}
else {
++head->hth_n_entries;
return NULL;
}
}INT_MAP_HT_REPLACE 函数相比 INT_MAP_HT_INSERT,多了对于重复数据的查找和替换。
需要注意的是:
INT_MAP_HT_REPLACE在插入时返回值为NULL,而在替换时返回值为被替换元素的地址,如果被替换元素空间是通过malloc等内存申请函数申请得到的,需要调用free等函数对空间进行释放。
删除
static inline struct Node * INT_MAP_HT_REMOVE(struct INT_MAP *head, struct Node *elm) {
struct Node **p, *r;
do {
(elm)->map_node.hte_hash = hashfn(elm);
} while (0);
p = INT_MAP_HT_FIND_P_(head,elm);
if (!p || !*p) return NULL;
r = *p;
*p = r->map_node.hte_next;
r->map_node.hte_next = NULL;
--head->hth_n_entries;
return r;
}
static inline struct Node ** INT_MAP_HT_NEXT_RMV(struct INT_MAP *head, struct Node **elm) {
unsigned h = ((*elm)->map_node.hte_hash);
*elm = (*elm)->map_node.hte_next;
--head->hth_n_entries;
if (*elm) return elm;
else {
unsigned b = (h % head->hth_table_length)+1;
while (b < head->hth_table_length) {
if (head->hth_table[b]) return &head->hth_table[b];
++b;
}
return NULL;
}
}删除操作本质就是一次查找与一次数组或链表操作,两个删除函数作用类似,但返回值存在区别:
INT_MAP_HT_REMOVE和INT_MAP_HT_REPLACE类似,返回值是被删除元素的地址。INT_MAP_HT_NEXT_RMV和INT_MAP_HT_FIND_P_类似,返回的是一个二级指针,指向的是保存被删除哈希元素的下一个元素地址的指针变量。 > 比如:hth_table[0]中保存着被删除元素的地址,hth_table[3]中保存着被删除元素的下一个元素地址,则该函数会删除hth_table[0]所指向元素的地址,并返回的hth_table[3]的地址信息。
两个删除操作均不会进行被删除元素的内存释放操作:
INT_MAP_HT_REMOVE返回被删除元素的地址,可通过返回值释放内存。INT_MAP_HT_NEXT_RMV需要在删除前保存被删除元素的地址信息,然后在删除操作之后释放内存。
参数检查
static inline void INT_MAP_HT_FOREACH_FN(struct INT_MAP *head, int (*fn)(struct Node *, void *), void *data)
{
unsigned idx;
struct Node **p, **nextp, *next;
if (!head->hth_table) return;
for (idx=0; idx < head->hth_table_length; ++idx) {
p = &head->hth_table[idx];
while (*p) {
nextp = &(*p)->map_node.hte_next;
next = *nextp;
if (fn(*p, data)) {
--head->hth_n_entries;
*p = next;
}
else p = nextp;
}
}
}调用 fn 函数检查每个哈希表中的元素,如果 fn 函数返回值非 0,则删除对应的元素。
注:如有需要,
fn函数中应对被删除元素进行内存释放
销毁
void INT_MAP_HT_CLEAR(struct INT_MAP *head) {
if (head->hth_table) free(head->hth_table);
INT_MAP_HT_INIT(head);
}该函数需要在哈希表清空后使用,否则会丢失哈希表中元素信息,导致一些 malloc 的空间无法释放,例如:
/* 自定义函数,非 libenent 宏定义生成函数 */
void INT_MAP_HT_CLEAR_ALL(struct INT_MAP * head) {
struct Node **ent, **next, *this;
for (ent = HT_START(INT_MAP, head); ent; ent = next) {
this = *ent;
next = HT_NEXT_RMV(INT_MAP, head, ent);
mm_free(this);
}
HT_CLEAR(INT_MAP, head);
}扩容
static unsigned INT_MAP_PRIMES[] = {
53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457, 1610612741
};
static unsigned INT_MAP_N_PRIMES = (unsigned)(sizeof(INT_MAP_PRIMES)/sizeof(INT_MAP_PRIMES[0]));
int INT_MAP_HT_GROW(struct INT_MAP *head, unsigned size) {
unsigned new_len, new_load_limit;
int prime_idx;
struct Node **new_table;
if (head->hth_prime_idx == (int)INT_MAP_N_PRIMES - 1) return 0;
if (head->hth_load_limit > size) return 0;
prime_idx = head->hth_prime_idx;
do {
new_len = INT_MAP_PRIMES[++prime_idx];
new_load_limit = (unsigned)(0.5*new_len); /* 0.5 为装载因子 */
} while (new_load_limit <= size && prime_idx < (int)INT_MAP_N_PRIMES);
if ((new_table = malloc(new_len*sizeof(struct Node*)))) {
unsigned b;
memset(new_table, 0, new_len*sizeof(struct Node*));
for (b = 0; b < head->hth_table_length; ++b) {
struct Node *elm, *next;
unsigned b2;
elm = head->hth_table[b];
while (elm) {
next = elm->map_node.hte_next;
b2 = ((elm)->map_node.hte_hash) % new_len;
elm->map_node.hte_next = new_table[b2];
new_table[b2] = elm;
elm = next;
}
}
if (head->hth_table) free(head->hth_table);
head->hth_table = new_table;
}
else {
unsigned b, b2;
new_table = realloc(head->hth_table, new_len*sizeof(struct Node*));
if (!new_table) return -1;
memset(new_table + head->hth_table_length, 0, (new_len - head->hth_table_length)*sizeof(struct Node*));
for (b = 0; b < head->hth_table_length; ++b) {
struct Node *e, **pE;
for (pE = &new_table[b], e = *pE; e != NULL; e = *pE) {
b2 = ((e)->map_node.hte_hash) % new_len;
if (b2 == b) pE = &e->map_node.hte_next;
else {
*pE = e->map_node.hte_next;
e->map_node.hte_next = new_table[b2];
new_table[b2] = e;
}
}
}
head->hth_table = new_table;
}
head->hth_table_length = new_len;
head->hth_prime_idx = prime_idx;
head->hth_load_limit = new_load_limit;
return 0;
}哈希表的扩容分为以下几个步骤:
- 根据装载因子、当前容量、当前数据量判断是否需要扩容
- 获取当前容量等级并计算需要扩容的等级
- 申请新的哈希表空间
- 重建哈希表,并释放旧空间
- 更新哈希表头信息
libevent采用的扩容方法方法的缺点是,容量扩张是一次完成的,期间要花很长时间一次转移hash表中的所有元素。这样在 hash 表每次扩容时,往里边插入一个元素将会等候很长的时间。